Hauptinhaltsblöcke
Abschnitt: M4 | Tratamento dos dados | Introdução à análise de dados on-line na pesquisa em Comunicação | ABERTO | | USP Extensão
-
Boas-vindas a você que começa o curso Introdução à Análise de Dados On-Line na Pesquisa em Comunicação. A preocupação central é formar pessoas com interesse em realizar pesquisas na internet.
Há duas formas de oferta. Em turmas de indivíduos matriculados e outra livre, autoinstrucional. Apenas a primeira oferecerá a certificação. A metodologia do curso, baseada na aprendizagem social, enfatiza a interação ativa com o ambiente e com as demais pessoas, de modo a fortalecer o desenvolvimento de uma atitude investigativa.
O curso possui sete módulos, cada um com duas atividades, além de um trabalho conclusivo. Os dois primeiros módulos oferecem um enquadramento geral da discussão. Os quatro módulos seguintes possuem atividades que se voltam aos interesses de cada um. O último módulo discute a questão da ética na pesquisa com dados digitais.
A proposta geral é que você realize reflexões e práticas que o capacitem a entender o papel dos dados digitais numa investigação.
Bons estudos.
Informado por pressupostos da pedagogia social, como a centralidade nos processos educativos do aprender a ser, o curso tem o objetivo de introduzir quem participa em discussões e práticas que envolvem o uso de dados on-line na pesquisa social, particularmente no campo da comunicação. No vídeo acima, é feita uma breve exposição sobre o conteúdo e o desenvolvimento dos trabalhos para a realização do curso. Você pode ver a página com Perguntas Frequentes [FAQ], o Código de Conduta, ter acesso ao PDF com a íntegra do curso e consultar todas as Referências do curso.
-
Módulo 4
Tratamento e gestão de dados
-
Estruturação e arranjo dos dados
Os dados poderão ser obtidos ou organizados a partir de diferentes modos, relacionados geralmente ao formato que possuem. Isso será relevante para dar legibilidade e favorecer a recuperação das informações, além de por vezes permitir tratamentos adicionais.
A maneira mais comum de estruturar dados é a tabular, com o uso de programas de edição de planilhas, como o Microsoft Excel, o LibreOffice Calc e o Google Sheets. Com mais frequência, as tabelas de planilhas contêm textos e números, mas é possível também reunir dados multimídia (imagens, gráficos, URLs). Diferentes formatos de dados podem ser combinados em planilhas. A imagem de abertura desse tópico deriva provavelmente de planilha com dados de coordenadas geográficas que se associam a dados sobre a quantidade de tweets com alguma palavra relacionada ao ódio. Depois, algum programa deu a forma gráfica que se visualiza.
Convém notar que, embora corriqueiramente os termos base de dados (database), conjunto de dados (dataset) e estrutura ou quadro de dados (dataframe) sejam utilizados de modo intercambiável, o primeiro é mais próprio de grandes quantidades de dados estruturados, enquanto os seguintes seriam mais aplicáveis a uma tabela simples.
Arquivos de textos, por vezes antes trabalhados em programas de planilha, podem conter dados que deem origem a redes ou grafos. Dados textuais complexos (entrevistas ou textos de páginas web) podem ser armazenados em programas de edição de texto, posteriormente tendo algum tipo de organização diferente, como a de nuvem de palavras. Pode ser relevante, conforme a investigação, salvar ou arquivar uma página (ou páginas) da web, a partir inclusive de programas, como já mostrado.
É possível ainda criar uma pasta na estrutura de arquivos do computador em que sejam inseridos dados coletados, com diferentes formatos, como vídeos, áudios, fotos, memes ou charges.
Um aspecto que favorece a confiabilidade da pesquisa é a possibilidade de outras pessoas, eventualmente e seguindo preceitos éticos, verificarem os chamados dados brutos – que podem ainda ser dados secundários de outras pesquisas. Nesse sentido, a reflexão sobre como manter e arquivar os dados coletados é importante, como instânia da gestão de dados.
Planilhas
Se você chegou até aqui, para a continuidade, um conhecimento básico sobre a manipulação de planilhas é relevante. Caso não o tenha, recomenda-se a consulta ao seguinte manual. -
Limpeza e refino dos dados

Antes de iniciar a análise de dados, com frequência é necessário realizar operações de limpeza e refino do que foi capturado. Uma recomendação importante é que seja feita uma cópia do arquivo com os dados brutos, de modo que, se ocorrer algum problema durante o trabalho, seja possível regressar ao que se coletou originalmente. Assim, na cópia, o trabalho de limpeza dos dados (data cleaning/cleansing) pode começar.
Tarefas de limpeza dos dados
- Remover dados irrelevantes;
- Eliminar dados duplicados redundantes;
- Reparar erros estruturais;
- Resolver casos de dados ausentes;
- Filtrar dados discrepantes;
- Verificar a precisão, a consistência e a uniformidade dos dados;
- Validar se os dados estão corretos.
Mesmo antes da limpeza, pode ser necessário fazer algum outro tipo de tratamento nos dados, para efeito de legibilidade, por exemplo: importar um arquivo em CSV ou JSON para o Excel. Há programas open source, como o OpenRefine, que fazem limpezas de dados. O próprio Google Planilhas possui ferramenta para isso, no caminho Dados > Limpeza de dados.
Questões técnicas, como a duplicação indevida de dados durante a captura, podem ser corrigidas pelos métodos expostos. Os dados devem ser padronizados e consistentes, o que pode exigir revisões nos formatos de dados de células ou uniformizar a grafia de palavras (por vezes, caracteres especiais geram informações com ruído). Em outras situações, a correção ou refino dos dados depende de uma avaliação mais criteriosa, levando em consideração aspectos como a efetiva necessidade de certos dados para a análise ou a pertinência ética de alterar ou excluir dados confidenciais de pessoas.
As práticas e reflexões feitas neste momento têm como objetivo assegurar a qualidade dos dados, geralmente, desdobrada em dimensões como:
Proporção, com relação aos dados obtidos, entre os que atendem aos requisitos desejados e os que têm falha ou ausência.
Exemplo: Se num questionário aplicado 10% das pessoas deixaram de responder a uma pergunta, isso diminui a completude dos dados.Inexistência de registros múltiplos sobre algo.
Exemplo: Um formulário respondido e registrado duas vezes por uma pessoa afeta negativamente essa dimensão.Grau em que os dados representam a realidade em determinado momento no tempo.
Exemplo: A atualidade dos dados de pesquisas eleitorais tende a decair rapidamente, diferentemente de dados sobre preferências por times de futebol.No sentido do dado se enquadrar (ser válido) quanto ao parâmetro esperado de alguma definição.
Exemplo: Se uma pergunta sobre quanto tempo alguém usa a internet por dia tem como resposta “esporte”, o dado é inválido.Capacidade do dado representar adequadamente o aspecto do mundo que procura refletir.
Exemplo: A data de nascimento de alguém reflete acuradamente a idade dessa pessoa.Dados consistentes são corroborados internamente, por outros dados do conjunto, ou por dados existentes em outros locais.
Exemplo: Se uma planilha possui dados em colunas com a data de nascimento e idade das pessoas, eles devem se confirmar mutuamente. Se não, há inconsistência. -
A estrutura de tabela Tidy Data

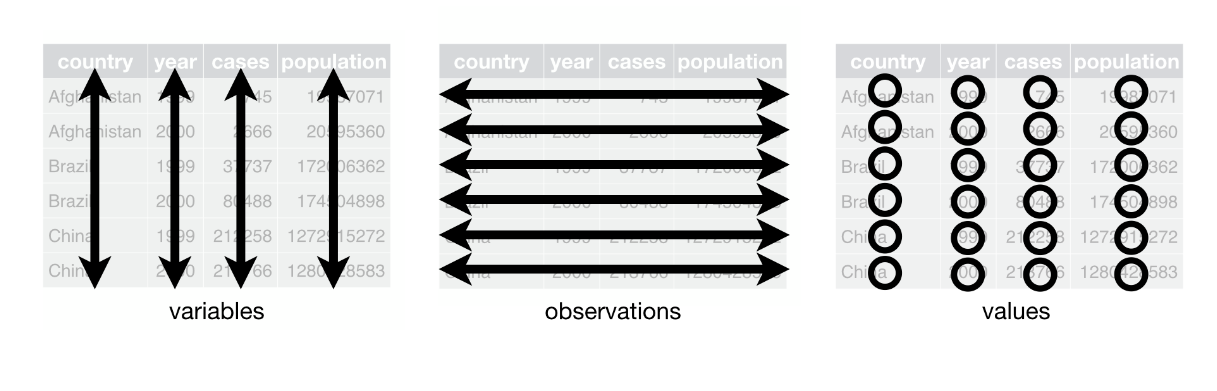
Uma noção importante relacionada à ordem de dados tabulares é a de dados organizados (tidy data), proposta por Hadley Wickham, um conhecido desenvolvedor da linguagem de programação estatística e gráfica R. A ideia básica é organizar os dados num padrão com três regras inter-relacionadas:
- Cada variável deve ter sua própria coluna.
- Cada observação deve ter sua própria linha.
- Cada valor deve ter sua própria célula.
Uma variável é qualquer característica ou medida de um fenômeno (como “nome”, “peso” e “altura”). As observações remetem a todos os valores descritos/medidos em uma mesma unidade (uma pessoa, um dia, uma nacionalidade etc.). Essas descrições são chamadas de valores, enquanto componente de alguma célula.
Embora nem toda tabela precise utilizar esse padrão, um ponto forte dessa proposta é a ligação entre as estruturas de organização físicas e semânticas dos dados. Essa padronização tem várias vantagens: o tempo de limpeza e organização de dados tende a ser menor, além disso, os dados no formato tidy são mais facilmente compreendidos e reproduzíveis por pessoas que compreendem a lógica do formato, sendo compatíveis com as ferramentas tradicionais de análise e produção de visualizações de dados utilizadas em linguagens como R e Python.
Entretanto, a plena compreensão do formato não é imediata, principalmente para quem está acostumado em trabalhar com planilhas eletrônicas, como observam certos autores. Vamos ver um exemplo comparado de tabela em formato de planilha tradicional e em tidy.
Tabela normal e tidy
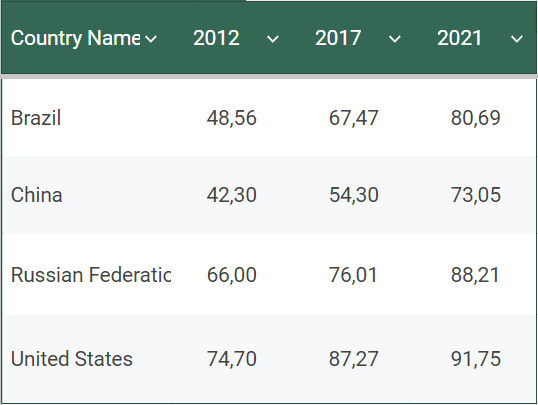
Dados tabulares comuns
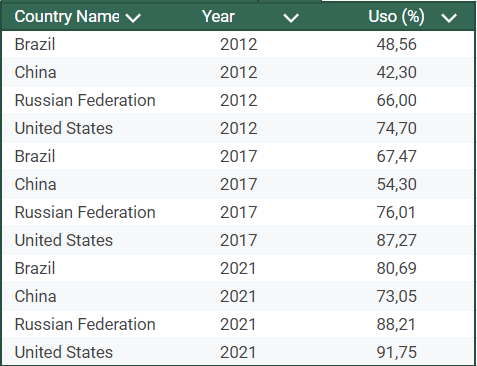
Dados tabulares em tidy
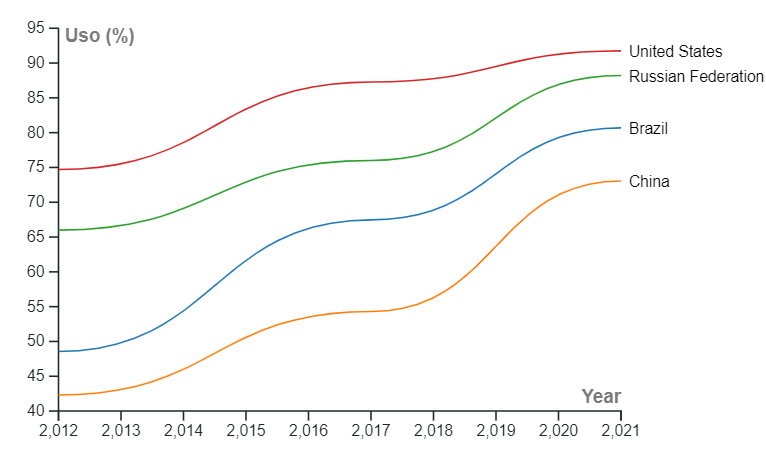
As duas tabelas foram elaboradas com os mesmos dados, obtidos do repositório de dados abertos do World Bank, mostrando índices percentuais da população que usa a internet em diferentes países. A tabela da esquerda não está em tidy, por colocar os anos e os indicadores percentuais como observações e não como variáveis. A tabela da direita gerará melhor plotagem (criação de imagem), como a mostrada abaixo, porém, poderia ser menos facilmente compreensível no corpo do texto de um artigo científico. Em suma, dependendo do objetivo de exposição do dado, o uso do formato tidy pode ou não ser adequado.
Faça a atividade na sequência, para consolidar seu entendimento do padrão tidy.

Pacotes de linguagens como R e Python possuem estratégias para a transformação de dados para o padrão tidy. No entanto, esse tópico não é abordado por este curso. Assim, é possível sugerir o auxílio de chatbots, nesse caso, verificando o acerto do resultado. Outra possibilidade é combinar o uso de recomendações de alguma IA com a conversão da tabela para o formato tidy, usando um programa como o Planilhas Google. Veja um exemplo. -
Teilnehmer/innen müssenEine Bewertung erhalten
Faça o exercício para consolidar seu conhecimento sobre as tabelas tidy.
-
Coleta e tratamento de dados como prévia das análises

As etapas de trabalho com dados não são estanques. Ao coletar e tratar dados, muitas vezes, começamos a planejar e mesmo a fazer, embrionariamente, a análise. O vídeo deste tutorial mostra a consolidação e tratamento dos dados coletados sobre revistas científicas, numa Planilha Google, destacando isso. Observe, ainda, as recomendações gerais para a organização de dados em planilhas.
A partir do próximo Módulo será feita referência a dados coletados até o momento, para os exemplos didáticos. Você deve ter conseguido coletar dados, como foi proposto, no entanto, se desejar poderá utilizar algum dos conjuntos abaixo para realizar exercícios práticos.
- Perfis seguidos por organizações feministas no Instagram (coleta manual)
- Principais influenciadores brasileiros (raspagem simples)
- Comparativo de recursos e gastos eleitorais de candidatos (dado importado do TSE)
- Matérias jornalísticas do Acervo da Folha de S.Paulo sobre Marielle Franco (coleta manual)
- Postagens de Guilherme Boulos no Instagram (coleta com o aplicativo Apify)
- Dados das revistas Qualis A de Comunicação, Google Acadêmico (2024/h5) (raspagem com Instant Data Scraper)
- Resultados de busca no Google sobre “Marielle Franco” (raspagem com Data Miner)
- Links dos sites das associações científicas Intercom e Compós (extração com Screaming Frog SEO Spider)
- Notícias on-line sobre Marielle Franco em veículos brasileiros (2021-2024) (coleta com Media Cloud)
- Verbetes da Wikipédia em língua portuguesa sobre Marielle Franco (coleta com Facepager)
- Lista de vídeos do canal do YouTube do Instituto Marielle Franco (coleta com YouTube Data Tools)
- Comentários no vídeo do canal do YouTube do Instituto Marielle Franco com mais interações deste tipo (coleta com YouTube Data Tools)
- Vídeos do YouTube com o termo “Marielle” (coleta com YouTube Data Tools)
- Postagens do TikTok com os termos “Boulos” e “cocaína” (coleta com aplicativo
4CAT)
Conjuntos de dados coletados
-
Gestão de dados

O gerenciamento ou gestão de dados é um processo que envolve o tratamento, a estruturação, o registro e o enriquecimento das informações relacionadas a eles. Desempenha, assim, um papel fundamental ao permitir a preservação e o compartilhamento de dados, assegurando sua contínua disponibilidade. As iniciativas e práticas adotadas num planejamento adequado devem possibilitar que conjuntos de dados relevantes sejam reaproveitados em diferentes iniciativas, em momentos e contextos variados.
Desse modo, dados de pesquisa geridos sob as concepções da ciência aberta podem, eventualmente combinados a outros conjuntos ou retrabalhados, ser insumo para outras investigações. Isso está relacionado à disponibilização pública dos dados. Conforme nota a Universidade de São Paulo, essa prática objetiva:
- possibilitar um avanço mais rápido das pesquisas da área, a partir do reuso e compartilhamentos dos dados gerados;
- possibilitar auditoria e reprodução de experimentos;
- aumentar a visibilidade da pesquisa;
- cumprir a obrigatoriedade de tornar públicos os dados, determinada por agentes fomentadores.
A preocupação é global e a redação de um Plano de Gestão de Dados (PGD), que acompanhe a submissão de um projeto de pesquisa, tem se tornado obrigatória, em algumas instituições de pesquisa e agências de fomento como a Fapesp. Por vezes, são oferecidos modelos sugeridos de PGD, como esse da USP. É importante conhecer as políticas sobre o assunto de instituições ou financiadoras às quais se queria submeter uma proposta de investigação.
De modo geral, o planejamento e a própria gestão de dados científicos devem procurar atender os princípios conhecidos como FAIR (Findable, Accessible, Interoperable, Reusable), divulgados nas comunidades científicas em todo o mundo. Em resumo, os dados científicos devem ser localizáveis, acessíveis, interoperáveis e reusáveis.
Saiba mais sobre o assunto, assistindo a esse vídeo. -
Geöffnet: Mittwoch, 21. Mai 2025, 00:00Fällig: Mittwoch, 28. Mai 2025, 00:00
A atividade propõe que você efetue o esboço de um Plano de Gestão de Dados para uma pesquisa que deseje realizar. O modelo da USP pode ser usado, assim como o de outra instituição que solicite esse tipo de documento. Redija o trabalho num processador de texto e o envie.